
The Notebook of Data: A 50-Year Journey Behind TRUNCATE and VACUUM in Apache Spark
 When researching for my upcoming book on Data Engineering, I decided to trace back the origins of some of the most “taken-for-granted” operations in Apache Spark — things like
When researching for my upcoming book on Data Engineering, I decided to trace back the origins of some of the most “taken-for-granted” operations in Apache Spark — things like TRUNCATE and VACUUM.
At first glance, these commands seem mundane — one clears a table, the other cleans up old files. But when you go down the rabbit hole, you realize they are descendants of some of the most profound computer science ideas ever invented.
This post is my attempt to tell that story — through the metaphor of a humble notebook, and the decades of innovation that turned it into the high-performance distributed data engines we use today.
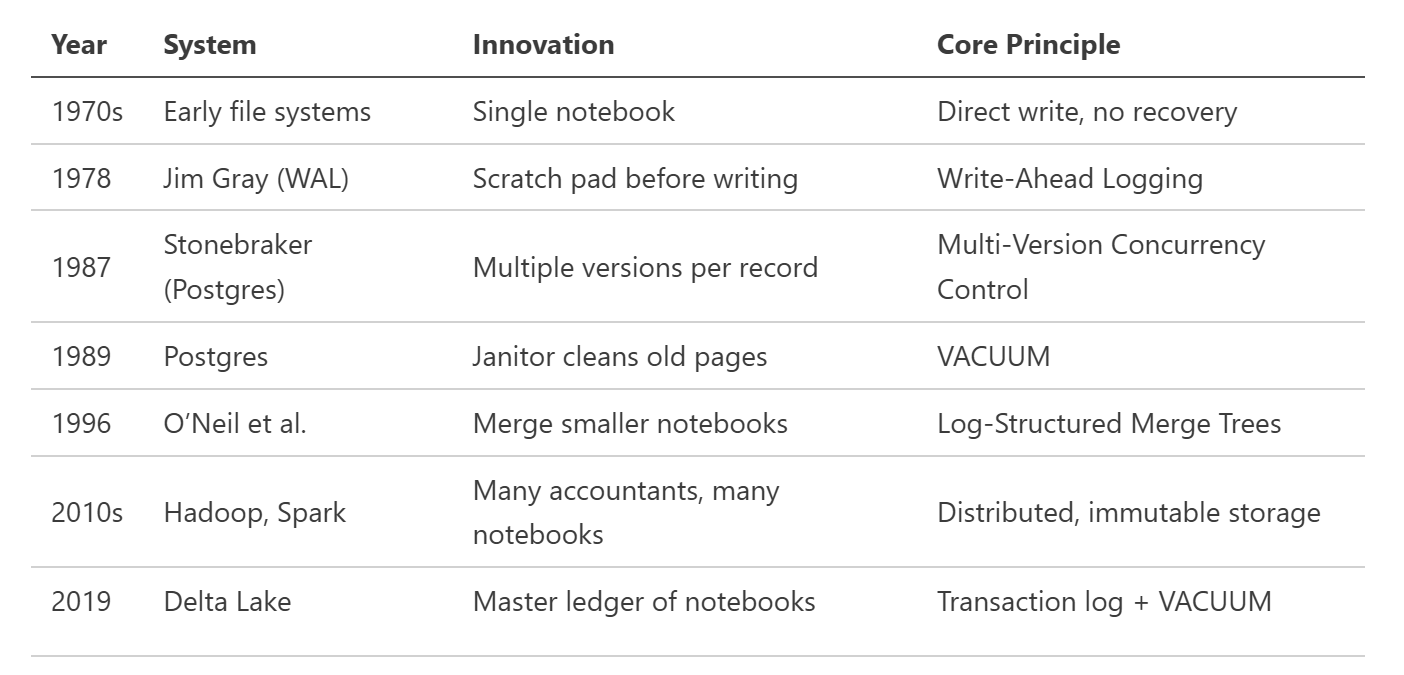
1. Writing It Down — The Paper Notebook Era (1970s)
 In the beginning, data systems were like a single accountant’s notebook. Every transaction was written directly, in ink.
No undo. No redo. Just raw, permanent data.
In the beginning, data systems were like a single accountant’s notebook. Every transaction was written directly, in ink.
No undo. No redo. Just raw, permanent data.
Mistakes? You’d cross them out and move on.
That was how early file-based databases worked — simple, direct, and brittle.
2. The Scratch Pad — Write-Ahead Logging (1978)

Then came Jim Gray and the idea that before writing anything to your main notebook, you should first jot it down on a scratch pad.
If you spill ink or crash mid-way, you can reconstruct everything from this pad. That principle became Write-Ahead Logging (WAL) — one of the cornerstones of the ACID guarantees that every modern database depends on.
It was the birth of atomic and durable transactions.
3. The Magic of Versions — MVCC (1980s)

As systems grew, multiple accountants started working on the same notebook at once. The chaos was real — overwrites, locks, deadlocks.
Enter Michael Stonebraker and Multi-Version Concurrency Control (MVCC) in Postgres (1987).
Now, instead of locking pages, each accountant worked on their own version of a record. Readers saw a consistent snapshot, while writers created a new one.
It was the foundation for modern snapshot isolation — what makes reads and writes peacefully coexist in PostgreSQL, Snowflake, and yes, even in Spark’s Delta Lake.
4. The Janitor — VACUUM (1989)

With so many versions floating around, notebooks started to bloat. Enter the janitor — the VACUUM process — whose job was to periodically tear out old, obsolete pages once no one was reading them.
PostgreSQL introduced this officially in 1989. It kept databases lean and efficient — and the name VACUUM stayed ever since.
5. Filing Notebooks for Scale — Log-Structured Merge Trees (1996)

Fast forward to the 1990s. The world was scaling up. One notebook was no longer enough. We now had filing cabinets full of smaller notebooks labeled Level 0, Level 1, Level 2…
We learned to write fast by simply adding new notebooks — and merge them later in batches. That was the Log-Structured Merge Tree (LSM Tree) invented by Patrick O’Neil in 1996.
If you’ve ever used Cassandra, LevelDB, or RocksDB, you’ve seen this principle in action. It’s also deeply embedded in Delta’s design — append now, compact later.
6. Distributed Accounting — Hadoop and Spark (2010s)

The internet age turned our filing cabinet into a global warehouse. Now, hundreds of accountants (workers) each managed their own pile of notebooks (data files).
Hadoop and later Apache Spark built on this philosophy — immutable files, distributed processing, fault tolerance. The idea of writing new notebooks instead of editing old ones became a global standard.
7. The Master Ledger — Delta Lake (2019)

Finally, came Delta Lake, uniting all these ideas into one elegant system.
A transaction log (_delta_log) acts as the master ledger, tracking which notebooks are “active” and which are “archived.”
When you run:
TRUNCATE TABLE my_table;
Delta simply adds a new entry in the ledger saying “no active notebooks exist” — a logical deletion.
And when you run:
VACUUM my_table;
Delta’s janitor walks into the warehouse and physically shreds the obsolete notebooks that are no longer referenced by any transaction — a physical cleanup.
That separation — logical vs physical deletion — is the direct legacy of 50 years of database research.
8. The Innovation Timeline
Reflections from the Research Trail
When you look closely, Apache Spark and Delta Lake are not just new tools — they are the latest chapters in an unbroken lineage of database evolution.
From Jim Gray’s log pad to Stonebraker’s multi-version pages, from the LSM filing cabinets to Delta’s digital ledger — each solved the same timeless problem:
How to keep writing faster, without ever losing truth.